
In this article· 6 sectionsJump to any section of the article
According to a recent research by Cambridge University’s Nicholas Boucher and Ross Anderson, there are two vulnerabilities that impact most code compilers.
These sorts of vulnerabilities have an impact on software supply chains; for example, if an attacker successfully commits code injection by deceiving human reviewers, future software is likely to inherit the vulnerability.
But let’s look at the technique:
- Extended strings: make sections of string literals seem as code, having the same impact as comments and causing string comparison to fail.
- Comment out: forces a comment to appear as code, which is then ignored.
- Early returns: bypass a function by running a return statement that seems to be inside a comment.
What happens next?
The compilers support this unique code that you do not see, when compiling your application they interpret it creating a compiled application different from the one you see in your IDE.
How Trojan Source works?
In this example I (Juan) will be an attacker, imagine that I publish a solution about how to do something (For example; I teach you how to check if a user is admin).
Let’s suppose a different scenario, you or your company have an open source project of something. I help you to develop some parts and I make a pull request with my contributions (I have provided a check so that certain action can only be done by Administrators, and you have added my code to your project).
Here you have the example:
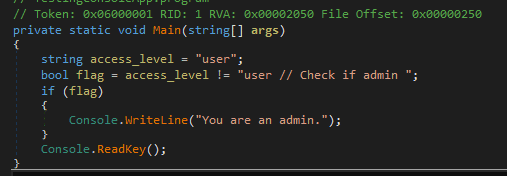
string access_level = "user";if (access_level != "user") //Check if admin { Console.WriteLine("You are an admin."); }The vulnerability is that this code contains Unicode characters that your IDE does not show you, let’s see this with a text editor that shows the hidden characters.

These characters modify the position, order, direction and so on of the text you see. So, what you see is not what it is.
You can read about how it works at here.
Well, now that you have accepted or copied my code, your project looks like this:

Apparently all is well, right?
Let’s run the application then:

But… HOW?
If it’s clear that access_level is "user"
And we are comparing whether it is different to "user"
So…
How the hell is "user" going to be different from "user"?
Because the compilation has been done after interpreting the hidden characters.
Let’s see this decompiled application (IL code):

As we can see in the compilation, the code is saying that if:
"user" ≠ "user // check if admin"The Admin instruction will be executed:
Console.WriteLine("You are an admin.");Obviously this is fulfilled, and it will be executed that we are admin (although in the source code we see the opposite).
Let’s see the result of the compilation in C#:
Completely different from the original… (But you have not realized this and now I am going to take advantage of it to execute functions of Admin on your application although I am not).
This example is simple, but I can inject a thousand instructions like this on your application in production and this is very dangerous.
How to solve it?
Fortunately, platforms like Github are warning users about this:

What should I do?
Interpreters, unicode-aware compilers and compiler pipelines must provide warnings or errors for unterminated bidirectional control characters in string literals or comments, as well as identifiers containing misleading mixed scripting characters.
Unterminated bidirectional string literals in comments and control characters should be explicitly forbidden by language requirements.
Mixed-script confused characters and bidirectional control characters should be highlighted with visual warnings or symbols in repository interfaces and code editors.
How to check if I have been affected by this vulnerability?
It’s all very well for Github to start notifying us about this, but… What if it has already happened to us?
Thinking about what solutions we could take in our team, I thought not the best, but the simplest.
In the end, the vulnerability is about injection of hidden characters in our source code, right, let’s check if in our source there is any file that contains something hidden.
As you are probably a .NET developer (you are reading the article of a cybersecurity community for .NET) we are going to create a small tool in .NET, to check this problem in our projects (guess which ones?) YES! .NET.
Let’s go 🚀
Solution
First, let’s check how to know if there are any hidden characters in a file:
var nonRenderingCategories = new UnicodeCategory[] { UnicodeCategory.Control, UnicodeCategory.OtherNotAssigned, UnicodeCategory.Format, UnicodeCategory.Surrogate };We use the enum of the UnicodeCategory we want to detect in our files.
We have more info on what they are in Microsoft Docs
As I have determined the unicode characters that could be associated with this vulnerability are of type:
- Control: with a Unicode value of U+007F, either in the range of U+0000 to U+001F or U+0080 to U+009F.
- OtherNotAssigned: Character that is not assigned to any Unicode category.
- Format: A format character that affects the layout of text or the operation of text processing, but is not normally present.
- Surrogate: Low substitute or high substitute character.
Now, the only thing we will do is, read a .cs file (C# source code file) where this vulnerability can be found:
var nonRenderingCategories = new UnicodeCategory[] {UnicodeCategory.Control,UnicodeCategory.OtherNotAssigned,UnicodeCategory.Format,UnicodeCategory.Surrogate };using StreamReader sr = new StreamReader(dotnetFile);while (sr.Peek() >= 0){ var c = (char)sr.Read(); var category = Char.GetUnicodeCategory(c); var isPrintable = Char.IsWhiteSpace(c) || !nonRenderingCategories.Contains(category); if (!isPrintable { alert(dotnetFile); issuesCount++; break; } } sr.Close();sr.Dispose();If the file contains one of these characters, we will suspect it.
Because the range of character types I have used is not exact, it may generate false positives if a file contains:
- Characters from other alphabets, such as Arabic: أعطني 3 تصفيق
- Special characters such as emoji: 👏👏👏
This solution will not be perfect, but it will warn you about possible problems and then you will evaluate if the file suffers the vulnerability.
This tool is finished and published in: TrojanSourceDetector4Dotnet
The tool allows you to scan one or more .NET projects for problems with this particular vulnerability.
As we at ByteHide are developers and we know how hard your life is, we offer you to install this tool through the console so that you don’t have to do anything and check in a few seconds all your projects.
Just open your CMD or Poweshell and type:
dotnet tool install --global TrojanSourceDetector --version 1.0.1
Now you will be able at any time to scan a directory where your .NET projects are located, to do this use:
TrojanSourceDetector and when it asks you for the directory indicate the full path.
For example place the CMD in your repository folder and run the command:

When finished, it will tell you which files may contain something suspicious:

and that’s it!
All thanks to https://www.trojansource.codes/
@article{boucher_trojansource_2021, title = {Trojan {Source}: {Invisible} {Vulnerabilities}}, author = {Nicholas Boucher and Ross Anderson}, year = {2021}, journal = {Preprint}, eprint = {2111.00169}, archivePrefix = {arXiv}, primaryClass = {cs.CR}, url = {https://arxiv.org/abs/2111.00169}}

