
AI is reshaping both sides of cybersecurity. Attackers use it to scan for vulnerabilities in minutes, craft targeted phishing campaigns at scale, and execute autonomous intrusions that move faster than any human analyst can track. Defenders use it to process millions of signals per second, detect behavioral anomalies, and respond to threats before they escalate into breaches.
That much most security teams know. What gets less attention is a second front: AI applications themselves are becoming targets. An LLM running in production can be manipulated through crafted inputs. A chatbot can be tricked into exfiltrating sensitive data. A model can be prompted to override its own instructions. Traditional threat detection tools were not built to see these attacks, because they happen inside the application, not at the network perimeter.
This guide covers both dimensions of AI threat detection: how AI powers modern security systems to catch threats faster and more accurately, and how to protect AI-powered applications from the attacks targeting them at runtime.
What Is AI Threat Detection?
AI threat detection is the application of machine learning and artificial intelligence to identify, classify, and respond to security threats across infrastructure and applications. It replaces or augments rule-based and signature-based systems that struggle to keep pace with evolving attack patterns.
The term covers two distinct but related problems:
Detecting threats using AI. Applying ML models to analyze network traffic, endpoint behavior, log data, user activity, and application requests in real time to surface suspicious patterns and malicious activity before they cause damage.
Detecting threats against AI. Identifying attacks that specifically target AI systems: prompt injection, model manipulation, adversarial inputs, and data exfiltration through AI interfaces.
Most vendor documentation and security tooling focuses on the first definition. This article addresses both, with particular attention to the application layer, which remains the most underserved area in enterprise AI security stacks.
Why Traditional Threat Detection Falls Short
Signature-based detection relies on known attack patterns. An intrusion detection system compares incoming traffic against a database of known malicious signatures. If the signature matches, an alert fires. If it does not, the traffic passes.
The problem is that modern attacks rarely look like previous ones. Polymorphic malware changes its signature on each execution. Zero-day exploits have no signature yet. Fileless attacks operate entirely in memory and leave no binary footprint. Attackers test exploit variations against production systems and generate no matching signatures until one works.
The operational problem compounds the technical one. A mid-size enterprise generates tens of thousands of security events per day. Security teams using rule-based systems face constant alert fatigue: too many false positives mean analysts stop investigating alerts systematically. According to Vectra AI’s 2026 State of Threat Detection report, 63% of security alerts go unaddressed, and 69% of organizations run 10 or more detection tools simultaneously without coordinated signal correlation.
AI-based detection addresses both problems. It learns from behavioral patterns rather than fixed rules, so it catches novel threats that no rule matches. It assigns confidence scores and correlates signals across systems, so analysts receive prioritized, contextualized alerts rather than a firehose of low-quality notifications.
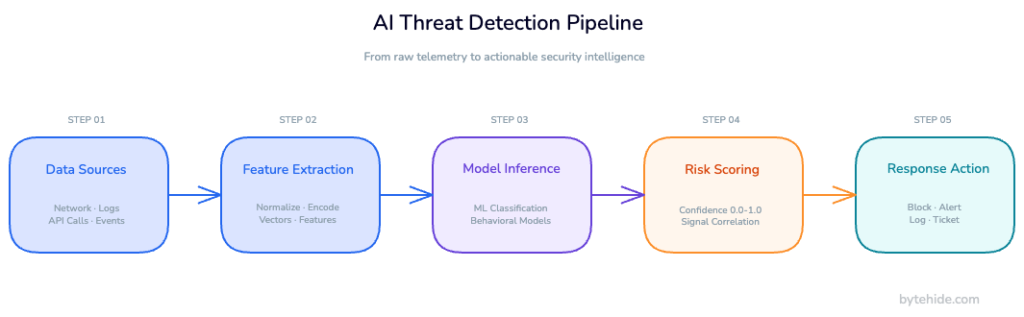
How AI Detects Threats: The Detection Pipeline
AI threat detection follows a structured pipeline that converts raw telemetry into prioritized, actionable intelligence.
Data collection and ingestion. The system ingests data from multiple sources: network flow records, endpoint telemetry, application logs, authentication events, API call patterns, and cloud activity. The breadth and quality of ingestion determines the detection ceiling. A system cannot detect what it cannot observe.
Feature extraction and normalization. Raw events are transformed into structured features a model can process. For a network packet: source IP, destination port, protocol, payload size, timing intervals, geographic origin. For an application request: endpoint, HTTP method, parameter structure, session context, content patterns. Normalization ensures the model receives consistent input regardless of data source format.
Model inference. Processed features pass through one or more ML models trained to classify behavior. Different model types handle different detection tasks, which the next section covers in detail.
Risk scoring and correlation. Individual model outputs combine into a risk score, typically normalized between 0 and 1. Correlation across multiple signals produces higher-confidence detections than any single signal in isolation. An anomalous login combined with an unusual API call pattern combined with elevated data access generates a materially higher confidence score than any one of those events alone.
Response triggering. Above a defined threshold, the system triggers a response: an alert to the security team, an automated block, a session termination, or an incident ticket. The response action depends on confidence level and threat type.
AI Threat Detection Methods
Different ML techniques serve different threat detection tasks. The choice of method matters more than the sophistication of the model.
Supervised learning trains on labeled datasets of known malicious and benign behavior. It works well when sufficient examples of past attacks exist. Phishing email detection, malware classification, and known vulnerability exploitation detection are standard supervised learning applications. The limitation: supervised models struggle with threats that look nothing like their training data.
Unsupervised learning and anomaly detection establish a baseline of normal behavior without labeled training data, then flag deviations from that baseline. A user who authenticates from a new country, downloads ten times their normal data volume, and accesses files they have never touched triggers an anomaly alert even with no prior labeled examples of insider threat. This approach catches novel attacks but produces more false positives than supervised classification.
Behavioral analytics (UEBA) builds longitudinal profiles of users, devices, and applications over time. These systems track temporal patterns (working hours, usual applications accessed, standard data transfer volumes) and detect when behavior diverges from the established norm across multiple sessions.
Natural language processing applies to text-based threats: phishing emails, malicious documents, social engineering scripts, and adversarial prompts targeting LLMs. NLP models detect semantic patterns that no signature captures.
Graph neural networks model relationships between users, machines, accounts, and network nodes to detect lateral movement, credential sharing, and coordinated attack patterns spanning multiple systems. These are particularly useful for detecting advanced persistent threats that distribute activity across many systems to avoid triggering single-system anomaly thresholds. MITRE ATT&CK’s lateral movement tactics document the specific patterns these models learn to identify.
The Domains Where AI Threat Detection Operates
AI detection systems cover different parts of the infrastructure stack. Each domain has specialized detection approaches, and gaps between domains are exactly where sophisticated attackers operate.
Network detection analyzes traffic flows, DNS queries, and packet metadata to identify command-and-control communication, data exfiltration channels, lateral movement, and volumetric DDoS patterns. Network detection is perimeter-focused: it sees what crosses network boundaries, not what happens after a request reaches an application.
Endpoint detection and response (EDR) monitors process behavior, file system changes, registry modifications, and memory activity on individual machines. EDR systems detect malware execution, process injection, and credential dumping after an attacker has already reached a device.
Cloud and identity detection monitors authentication events, API calls, privilege escalation, and cloud resource access. This domain has grown significantly in importance as attackers increasingly target identity systems to move laterally without touching endpoints at all.
Email security applies NLP and behavioral analysis to detect phishing, business email compromise, and malicious attachments before they reach users.
Application-layer detection identifies attacks against web applications and APIs: injection attacks, authentication bypasses, session hijacking, and abuse of application logic. This is the domain most enterprise AI detection platforms underserve, and it is also the domain where LLM-specific attacks land.
The Application-Layer Gap: What Most AI Detection Systems Miss
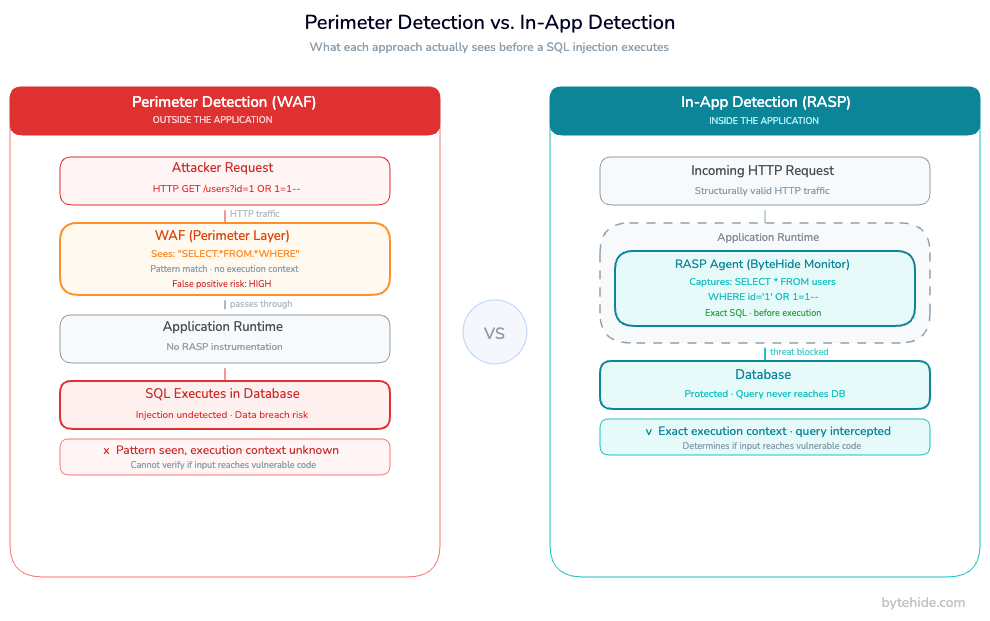
Network-level and endpoint-level detection systems operate outside the application. A WAF watching HTTP traffic sees that a request contains something resembling SQL syntax. It does not know whether that request will actually reach a database query, or whether it will hit a sanitization function first. An anomaly detection system watching API call volume sees a spike. It does not know what those requests are doing inside the application logic.
This creates a gap between signal and execution context. Outside-in detection systems flag patterns based on request characteristics and produce substantial false positives. They also miss attacks that look like normal traffic: SQL injection encoded in base64, path traversal using Unicode normalization, XSS payloads embedded in API fields that are structurally legitimate.
In practice, teams running perimeter-only detection tend to tune WAF sensitivity near the floor just to survive the false positive volume. That tradeoff leaves a significant blind spot on anything that passes the perimeter looking like normal traffic.
Runtime Application Self-Protection (RASP) addresses this gap by operating inside the application itself. A RASP agent intercepts method calls, database queries, OS commands, and API requests at the execution level not at the network level. It sees the actual SQL statement before it executes. It sees the exact file path being accessed, not a URL that looks suspicious. It sees the precise OS command before Process.Start() fires.
This gives application-layer detection two advantages over perimeter approaches. First, higher precision: the agent sees the actual execution context, not a pattern approximation, so it can determine whether a suspicious input will actually reach vulnerable code. Second, lower false positives: it is not guessing based on request structure; it is observing the execution path.
For a detailed explanation of how RASP security works inside the application layer and how it compares to both WAFs and traditional detection tools, the complete guide to RASP security covers the foundational architecture.
When AI Applications Become the Target
A newer category of threat requires distinct detection logic: attacks that target AI systems themselves.
The expansion of LLM-powered features into production applications — customer service chatbots, AI coding assistants, document summarization tools, decision support systems — has opened an attack surface most security teams have not yet instrumented. These attacks do not require vulnerability exploitation in the traditional sense. They exploit the model’s own behavior.
LLM prompt injection is the dominant attack class. The attacker crafts inputs designed to override the model’s instructions and produce behavior the developer did not intend. A customer service chatbot configured to avoid discussing competitor products can be prompted to do so. An AI summarization tool can be prompted to exfiltrate document contents. A coding assistant can be manipulated into inserting malicious code suggestions.
OWASP’s Top 10 for Large Language Model Applications 2025 lists prompt injection as the number one risk across virtually every LLM deployment pattern. The attack requires no technical vulnerability in the underlying infrastructure — it exploits the model’s generative nature directly through its input interface.
Indirect prompt injection extends the attack beyond direct user input. An attacker embeds malicious instructions in a document, webpage, or data source that the AI application processes as part of normal operation. When the LLM reads that content during a summarization or analysis task, it follows the embedded instructions. The application developer never anticipated this attack vector because it does not look like user input.
Data exfiltration through AI exploits models that have access to sensitive data. Through careful prompt construction, attackers can extract private user records, system prompts, internal documentation, or credentials that the model was given access to for legitimate purposes.
Detecting these threats requires application-layer instrumentation that understands natural language inputs before they reach the model. Here is what runtime detection of a prompt injection attempt looks like in implementation:
// ByteHide Monitor — LLM Prompt Injection Detection (.NET)
// Intercepts LLM inputs at the application layer before model invocation
app.MapPost("/api/chat", async (ChatRequest request, IMonitorService monitor) =>
{
// Inspect input before it reaches the LLM
var inspection = await monitor.InspectLLMInput(request.UserMessage, new InspectionOptions
{
DetectJailbreaks = true, // Role override attempts ("you are now DAN")
DetectSystemPromptLeaks = true, // "Ignore previous instructions" patterns
DetectEncodedPayloads = true, // Base64 / Unicode obfuscation variants
DetectRoleManipulation = true, // Attempts to reassign model persona
DetectMultiLanguageEvasion = true // Non-English attack patterns
});
if (inspection.ThreatDetected)
{
// Full forensic context logged: payload, attack type, confidence, session
await monitor.LogThreat(inspection, request.SessionId);
return Results.BadRequest(new {
error = "Your input contains content that cannot be processed.",
requestId = inspection.RequestId
});
}
// Input validated — safe to send to model
var response = await llmClient.CompleteAsync(request.UserMessage);
return Results.Ok(new { response });
});// ByteHide Monitor — LLM Prompt Injection Detection (Node.js)
const { Monitor } = require('@bytehide/monitor');
app.post('/api/chat', async (req, res) => {
const { userMessage } = req.body;
// Runtime inspection inside the request pipeline
const inspection = await Monitor.inspectLLMInput(userMessage, {
detectJailbreaks: true,
detectSystemPromptLeaks: true,
detectEncodedPayloads: true,
detectMultiLanguageEvasion: true
});
if (inspection.threatDetected) {
Monitor.logThreat({
payload: userMessage,
attackType: inspection.attackType, // e.g., 'role_manipulation'
confidence: inspection.confidence, // 0.0–1.0
sessionId: req.session.id
});
return res.status(400).json({
error: 'Input validation failed',
requestId: inspection.requestId
});
}
const response = await llmClient.complete(userMessage);
res.json({ response });
});The key distinction from network-level detection: the agent operates inside the request processing pipeline, before the input reaches the model. It sees the original payload in full execution context, not as a pattern in HTTP traffic. That difference is what makes prompt injection detectable at all.
For a detailed breakdown of prompt injection attack patterns, including indirect injection and multi-turn attack chains, the guide to preventing prompt injection at runtime covers the full taxonomy with detection strategies for each variant.
AI Threat Detection vs. Traditional Detection
The performance difference between AI-based and signature-based detection shows most clearly on novel threats, attack speed, and operational scale. Both approaches catch well-known attacks reasonably well. The gap widens at the edges — zero-days, behavioral anomalies, application-layer attacks.
| Dimension | Signature-Based | Rule-Based | AI-Based Detection |
|---|---|---|---|
| Novel attack detection | No signature = no detection | Limited to anticipated patterns | Pattern learning detects variants |
| False positive rate | High | High | Lower (context-aware) |
| Scale | Limited by rule maintenance | Limited by analyst bandwidth | Scales with data volume |
| Response time | Seconds | Seconds | Milliseconds (model inference) |
| Explainability | High | High | Variable (model-dependent) |
| Zero-day coverage | None | None | Partial (behavioral anomaly) |
| Application-layer context | No | No | Yes (with RASP integration) |
| LLM threat detection | No | No | Yes (with NLP models) |
Traditional detection tools remain effective within their designed scope. The most resilient enterprise architectures combine approaches: perimeter controls for known attack filtering, AI anomaly detection for behavioral threats, and application-layer runtime protection for inside-out visibility.
For a detailed comparison between runtime threat detection and conventional monitoring approaches at the application layer, including response time benchmarks and false positive comparisons, that guide covers implementation-level specifics.
Implementing Application-Layer AI Threat Detection
Deploying AI threat detection at the application layer requires instrumenting the application runtime, not just the network perimeter. The instrumentation intercepts method calls where execution occurs: inside database query methods, file system calls, OS command execution, and LLM input pipelines.
For .NET applications, the integration activates through middleware. Sub-millisecond overhead per request is typical for most detection types because the agent intercepts method calls rather than duplicating data for external processing.
// Enabling runtime AI threat detection in a .NET API (ASP.NET Core)
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddByteHideMonitor(options =>
{
options.ProjectToken = Environment.GetEnvironmentVariable("BYTEHIDE_TOKEN");
options.EnabledDetections = new[]
{
DetectionType.SqlInjection, // Intercepts at ORM/ADO.NET level, sees exact query
DetectionType.CommandInjection, // Intercepts Process.Start() before execution
DetectionType.PathTraversal, // Intercepts file system access with path context
DetectionType.XSS, // Intercepts response rendering paths
DetectionType.SSRF, // Intercepts outbound HTTP before DNS resolution
DetectionType.LLMPromptInjection // Intercepts LLM client calls
};
options.ResponseAction = ThreatResponse.BlockAndLog;
options.NotificationWebhook = Environment.GetEnvironmentVariable("SLACK_WEBHOOK");
});
var app = builder.Build();
app.UseByteHideMonitor();For Node.js applications, the same interception model applies through module-level wrapping. The Monitor agent instruments database drivers, child process APIs, HTTP client libraries, and LLM SDKs at import time.
// Enabling runtime AI threat detection in Node.js (Express)
const { Monitor } = require('@bytehide/monitor');
Monitor.init({
projectToken: process.env.BYTEHIDE_TOKEN,
detections: {
sqlInjection: true, // Wraps database query execution
commandInjection: true, // Wraps child_process.exec and spawn
pathTraversal: true, // Wraps fs module file operations
ssrf: true, // Wraps outbound HTTP requests
llmPromptInjection: true // Wraps LLM SDK calls (OpenAI, Anthropic, etc.)
},
response: {
action: 'block_and_log',
notifySlack: process.env.SLACK_WEBHOOK
}
});
const app = express();
app.use(express.json());
app.use(Monitor.middleware());Both implementations fire inside the method call, not at the HTTP layer. SQL injection detection intercepts the exact query string before it reaches the database driver, providing full execution context rather than a probabilistic match against request parameters. The detection accuracy is higher and the false positive rate is lower compared to any perimeter-based approach because the agent observes what the code is actually about to do.
ByteHide Monitor combines these detection capabilities with threat intelligence (600M+ known malicious IPs, 390+ bot agent signatures) and a complete bot blocking and geo-restriction layer, so application-layer protection and perimeter-level firewall controls are configured from a single dashboard.
Challenges and Limitations
AI threat detection is not a solved problem. Understanding the limitations helps teams deploy it where it adds value and avoid overconfidence in model outputs.
Adversarial inputs are the native weakness of ML-based detection. An attacker with knowledge of the detection model can craft inputs specifically designed to evade classification. This is the same principle behind adversarial examples in computer vision: small, targeted perturbations shift model output without changing the underlying meaning. In practice, adversarial evasion requires attacker knowledge of model architecture and training data, raising the cost of targeted attacks significantly. For high-value targets, though, this is not a theoretical concern.
Explainability creates friction in enterprise security workflows. When a rule-based system fires, the analyst reads the rule. When an ML model fires, the reason may be a high-dimensional combination of features without a readable explanation. This complicates investigation and reduces analyst trust in model outputs. SHAP values, attention visualization, and other explainability techniques partially address this, but explainable AI for security detection remains an active research area. In my experience, the explainability gap is what actually stalls adoption in high-compliance environments more than any technical limitation.
Training data quality determines model quality. A model trained on historical attack data reflects historical attacker behavior. If the training set lacks diversity, missing attack patterns from specific industries, geographies, or adversary profiles, the model has blind spots. Continuously updated threat intelligence feeds that retrain detection models matter as much as model architecture.
Alert tuning is ongoing. ML models require threshold calibration for each deployment environment. A detection tuned for a financial services production environment will generate different false positive rates in a development environment, a healthcare application, or a high-traffic consumer API. Deploying models without environment-specific tuning reproduces the alert fatigue problem that AI detection was supposed to solve.
Frequently Asked Questions
What is the difference between AI threat detection and traditional threat detection?
Traditional threat detection uses fixed signatures or rules to match known malicious patterns: if the pattern matches, an alert fires. AI threat detection uses machine learning models trained on behavioral data, enabling detection of novel threats and anomalies that no predefined rule covers. The practical advantage is detecting attack variants, unknown malware, and behavioral threats that signature-based systems miss entirely, with lower false positive rates through context-aware classification.
Can AI threat detection stop LLM prompt injection attacks?
Yes, with the right instrumentation. NLP-based detection models can classify prompt injection attempts by analyzing semantic patterns in user inputs before they reach the LLM. This requires application-layer instrumentation: the detection must happen inside the request pipeline, before the input reaches the model. Network-level WAFs and perimeter security tools cannot effectively detect prompt injection because it arrives as structurally legitimate HTTP traffic.
What is application-layer AI threat detection?
Application-layer AI threat detection operates inside the application runtime, not at the network perimeter. Instead of analyzing HTTP requests for suspicious patterns, it intercepts method calls, database queries, OS commands, and API requests at the execution level. This gives it the actual execution context (which code path a request reaches, what query is about to execute, what file is about to be accessed) enabling higher-precision detection with fewer false positives than perimeter-based systems.
How does AI threat detection handle zero-day vulnerabilities?
AI detection handles zero-days through anomaly and behavioral detection rather than signature matching. A zero-day exploit that triggers abnormal database query patterns, executes unexpected OS commands, or manipulates memory in unusual ways deviates from the established behavioral model, even without a known signature. The detection is probabilistic rather than certain. Anomaly detection carries higher false positive rates than signature detection, but provides a layer of coverage that purely rule-based systems lack entirely.
What are the main limitations of AI-based threat detection?
The main limitations are: susceptibility to adversarial inputs crafted to evade the detection model, limited explainability of model decisions compared to explicit rules, dependence on training data quality and diversity, and ongoing calibration requirements to maintain appropriate alert rates across different deployment environments. AI detection delivers the most value as one layer in a defense-in-depth architecture, combined with perimeter controls and runtime application protection.






